
В одном из майских релизов у нас вышел AI-помощник, который помогает пользователям разобраться в системе. Мы решили подготовить большой материал на основе внутренней презентации для команды разработки.
Мы бы могли сразу сказать, что наш АI-помощник самый технологичный ИИ в решениях для управления проектами, но это было бы лукавством. Timetta действительно использует наиболее современные подходы к внедрению ИИ, однако важны детали.
Поэтому мы решили подробно рассказать о том, как устроены современные языковые модели и как они помогают улучшить пользовательский опыт в Timetta.
Как работают языковые модели
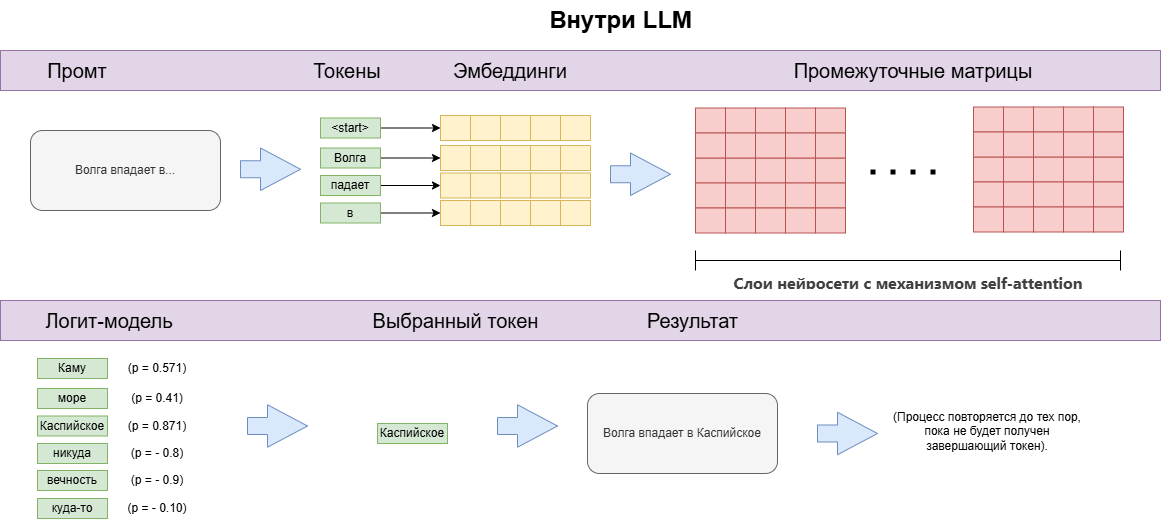
LLM (large language models, или большие языковые модели) — это алгоритмы, которые вначале превращают текст в числовое представление, а затем учатся находить в полученных числах закономерности.
LLM не понимает текст в привычном смысле, а выявляет статистические закономерности в данных.
Рассмотрим самую простую схему обучения языковой модели. Она состоит из трёх элементов: данные, архитектура и обучение.
- Для обучения LLM нужно огромное количество текстов. Чем больше данных будет у модели, тем проще найти устойчивые закономерности. Источниками данных служат интернет, книги, статьи, справочники и многое другое.
- Вся информация проходит через специальную архитектуру нейросети, которая задаёт структуру обработки данных.
- Обучение — это процесс оптимизации параметров модели: корректировка внутренних весов с целью подстроиться под полученные данные.
- На выходе получается обученная языковая модель.
Весь секрет LLM в том, что она поэтапно угадывает следующий фрагмент текста. LLM работает рекуррентно. У LLM есть огромный словарь всех доступных слов. На каждом шаге генерации ответа модель старается выбрать наиболее вероятное слово, исходя из контекста.
Получив запрос, модель предсказывает на его основе наиболее вероятное первое слово в ответе. Затем добавляет полученное в ответе слово к запросу и снова делает предсказание. Процесс повторяется, пока не будет сгенерирован полный ответ.
Токенизация
На самом деле LLM оперирует не словами, а токенами. Если упростить до предела, то токен — это сочетание букв, которому присвоено числовое значение (вектор). Токеном может оказаться как одна буква, так и целое слово.
Словарь языковой модели составлен из таких токенов. Для получения токенов используют отдельные алгоритмы, которые вычленяют наиболее часто повторяющиеся сочетания букв и символов.
Эмбеддинги
Эмбеддинги — это векторные представления токенов. Эмбеддинги появляются в процессе обучения самой языковой модели.
Эмбеддинги можно представить как числовые векторы, расположенные в многомерном пространстве.
Интуитивный пример для понимания
Для иллюстрации к понятию эмбеддинга можно привести такой пример:
Слова мужчина и женщина находятся примерно на таком же расстоянии друг от друга, что и слова король и королева.
Если судить по аналогии, то можно сказать, что каждое число в векторе представляет собой какой-то скрытый признак. Например, у слова мужчина могут быть такие признаки: «живое существо», «человек», «пол», «раса» и т. д.
Пространство, в котором расположены эмбеддинги, многомерно. Чем сложнее модель, тем больше размерность. Например, в GPT-3 насчитается до 12288 измерений.
Матрицы
Матрица — это хранилище всех знаний нейросети в виде прямоугольных таблиц чисел, которые кодируют информацию и задают правила преобразования данных. Матрицы бывают разных типов:
- Матрицы эмбеддингов — служат для преобразования токенов в векторы.
- Матрицы весов — хранят обучаемые параметры модели.
- Выходные матрицы — предсказывают наиболее вероятный ответ.
Матрицы участвуют в обработке пользовательского запроса путем различных операций с эмбеддингами: умножение, вычитание, сложение, повторение и т. д.
По сути LLM — это очень сложная математическая функция с большим количеством обучаемых весов. Очень примитивно модель работы LLM можно описать следующим образом:
- Пользователь отправляет запрос модели.
- Запрос разбивается на токены.
- Каждый токен заменяется на вектор из матрицы эмбеддингов.
- Эмбеддинги проходят через серию матричных операций.
- Модель получает вероятность распределения токенов в ответе и выбирает из них наиболее подходящий.
- Процесс повторяется.
Некоторые методы позволяют управлять поведением модели: например, усиливать вероятность менее ожидаемых токенов для получения более разнообразных и контекстно-чувствительных ответов.
Небольшое резюме
Запрос пользователя LLM воспринимает как задачу подобрать наиболее вероятное продолжение предложенному фрагменту текста. LLM подбирает ответ на основании всего, чему она была обучена.
Методы дообучения языковых моделей
Для обучения языковых моделей требуется огромное количество данных, вычислительных ресурсов и электроэнергии. Однако при создании узкоспециализированных решений применяют более экономные подходы, основанные на дообучении уже существующих моделей. Существуют два основных метода дообучения: Fine-tuning и RAG. Все остальные методы являются производными от них.
Основные различия двух методов
| Fine-tuning | RAG |
|---|---|
| Требует переобучения при обновлении данных | Подходит для обновляемых данных |
| Требует разметки и подготовки около 2-10 тыс. примеров | Не требует серьезной подготовки данных |
| Позволяет задать нужный формат ответов, стиль общения, терминологию | Подходит для поиска по внешним базам данных — векторным, графовым, реляционным |
| Информация интегрируется напрямую в нейросеть, поэтому небезопасно для чувствительных данных | Обеспечивает безопасность данных, можно интегрировать ролевую модель |
| Дорого: нужно много вычислительных ресурсов и огромный датасет | Относительно дешево |
Первое, что приходит в голову, при создании сервиса на основе LLM — нужно просто дообучить модель на основе нужных данных. Это как раз и есть метод Fine-tuning. Проблема этого метода в том, что у больших языковых моделей миллиарды параметров. Для качественного дообучения потребуются сотни GPU, очень много времени, денег и, что самое проблематичное, огромный датасет. Даже для обучения отдельных небольших матриц внутри модели потребуется не менее 2 000 примеров, а до полного дообучения — минимум 100 000. При этом не получится гибко адаптироваться к точечным изменениям. Например, изменился термин в справке — придется заново дообучать всю модель.
Для небольших компаний и узкопрофильных задач была придумана архитектура RAG (Retrieval-Augmented Generation), которая сочетает генерацию текста и поиск информации из внешних источников. Такой подход не требует большого количества размеченных данных и хорошо подходит для мультиагентных систем. RAG позволяет удешевить и ускорить разработку AI-сервисов.
RAG предполагает, что ответ заранее обученной языковой модели будет дополнен различными кусочками информации, найденными во внешних источниках. Например, в корпоративной вики, справке или базе знаний. Основная сложность RAG заключается в поиске релевантной информации внутри датасета. Есть несколько методов поиска релевантной информации.
Методы поиска релевантной информации
- Text Search (BM25) — поиск по совпадению слов, учитывается их частность.
- Vector Search — поиск по близости эмбеддингов.
- Hybrid Search — комбинация первых двух методов через пересчёт весов на выходе.
- Поиск по ключевым словам.
- Фильтрация по метадате, категории и т. д.
У каждого метода есть свои особенности и области применения. Например, Text Search (BM25) позволяет работать с частотностью слов. Если какое-то слово встречается в тексте слишком часто, то, возможно, оно не очень важно.
Как архитектура RAG используется на практике
RAG удобно использовать при разработке чат-ботов и виртуальных помощников. При наличии подробной базы знаний, можно реализовать следующий конвейер (pipeline) для обработки запросов пользователя.
- Все данные берутся из какого-нибудь готового источника — базы знаний, справки, технической документации, корпоративной вики. Чем больше информации — тем лучше.
- Все тексты из базы знаний разбиваются на отдельные фрагменты для улучшения качества поиска.
- Полученные фрагменты документов переводятся в векторы.
- Все векторы хранятся в базе данных, которая оптимизирована для поиска по близости векторов.
Когда пользователь задаёт вопрос AI-помощнику, запрос также превращается в эмбеддинг. Система находит наиболее релевантные фрагменты в базе знаний, а затем LLM использует эти фрагменты при формировании ответа.
Как устроен AI-помощник в Timetta
AI-помощник появился в Timetta в начале мая. Помощник помогает отвечать на вопросы пользователей по работе в системе на основе информации из справки. Пользователь, находясь в системе, может открыть окно чата, задать вопрос и сразу же получить ответ.
Timetta использует стандартную модель взаимодействия с RAG-архитектурой. AI-помощник превращает запрос пользователя в эмбеддинг, затем ищет похожие вектора в векторной базе данных, находит самые подходящие и берет соответствующие этим векторам фрагменты текстов. Затем вопрос пользователя вместе с найденными фрагментами документов передается языковой модели.
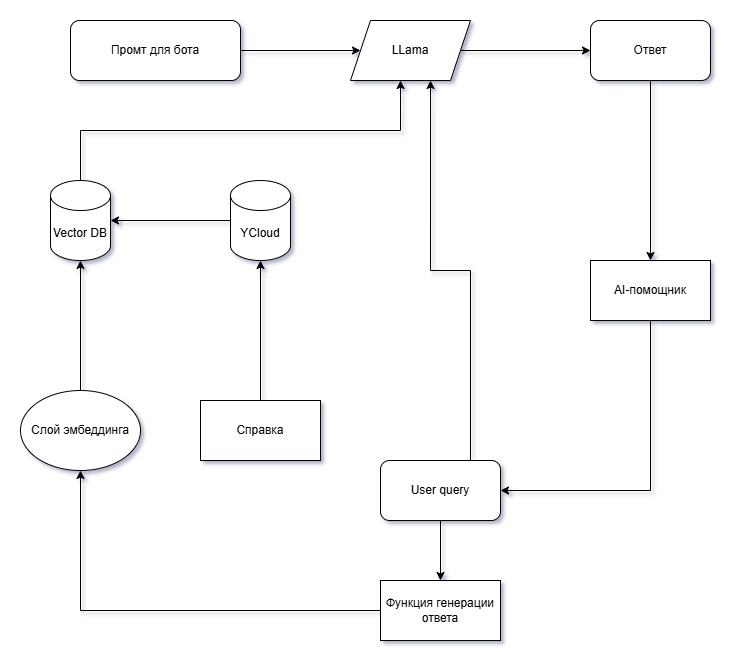
Timetta использует для обработки запросов пользователей инфраструктуру Яндекса — векторную базу данных и средства векторизации текста. В качестве языковой модели Timetta использует нейросеть Llama, которая развернута на все тех же серверах Яндекса. Такая модель инфраструктуры удобна тем, что ее можно быстро развернуть, однако есть и недостатки. За обработку токенов приходится платить, а еще Яндекс ограничивает доступ к настройкам векторной базы данных. При масштабировании системы и усложнении задач придется искать другое решение.
Для чего нужен AI-помощник в Timetta?
60% вопросов в поддержку — типовые. Ответы на них уже есть в справке, но пользователям не всегда удаётся их быстро найти. Вручную обрабатывать такие запросы — долго и неэффективно: это отвлекает специалистов от сложных задач, а клиенты ждут ответа.
AI-помощник решает эту проблему:
- Автоматически отвечает на 60% запросов — освобождая время поддержки для нестандартных случаев.
- Находит ответы в справке за секунды — даже если пользователь не знает точных формулировок.
- Даёт чёткие инструкции — например, пошагово объясняет, как настроить отчёт или исправить ошибку.
- Помогает новичкам — быстро адаптирует их к системе, сокращая время на обучение.
Результат:
- Пользователи получают помощь мгновенно — без ожидания ответа от поддержки.
- Специалисты фокусируются на сложных задачах — там, где нужен человеческий опыт.
AI-помощник — это не замена технической поддержки, а дополнение к ее работе. Помощник делает работу поддержки быстрее, удобнее и эффективнее.
О перспективах развития AI-помощника в Timetta
LLM можно использовать в качестве оркестратора для мультиагентных систем. Один агент ищет информацию по векторной базе данных, другой — информацию в интернете, третий — рецензирует тексты, четвертый — помогает составлять запросы OData и т. д. LLM умеет самостоятельно классифицировать запросы и выбирать нужного агента. Это позволяет расширить возможности поиска, использовать не только векторные базы данных, но также графовые, реляционные и другие. Примером здесь можно назвать Deepseek, у которого функцию поиска в интернете выполняет как раз один из таких агентов.
Применительно к Timetta эта возможность LLM выступать в качестве оркестратора позволит в будущем улучшить качество технического обслуживания системы. Например, можно помочь администраторам системы генерировать запросы по API, создавать обработчики на языке C# и решать другие прикладные задачи.
Вот несколько примеров того, что должно появиться в Timetta:
- Использовать сторонние методические материалы (из открытых источников, находящихся в public domain, чтобы не нарушать авторского права) для ответа на общие методологические вопросы. Например, пользователь может задать вопрос, какие подходы используют для управления ресурсами и какие из них поддерживает Timetta.
- Использовать данные абонента для помощи в управлении проектами. Например, пользователь может спросить, в каких проектах сотрудники перерабатывают.
- Использовать обезличенные данные всех абонентов для прогнозирования событий проекта. Например, пользователь может спросить, какие сотрудники находятся на грани выгорания.
- Использовать ИИ для поддержки принятия решений. Например, бот может подобрать сотрудников на проект.
Некоторые трудности и актуальные проблемы имплементации ИИ
LLM — не серебряная пуля. У технологии есть ряд серьезных ограничений и уязвимостей, о которых нужно знать.
- Запросы к LLM стоят денег. Не очень больших, но на длинной дистанции стоимость может стать значительной. Чем больше запросов будет обрабатывать система, тем дороже она стоит.
- Нужны качественные данные. Качество ответов напрямую зависит от источников информации, с которым работает LLM. Чтобы пользователь получал качественные ответы, нужна не столько сложная LLM, сколько подробная, хорошо структурированная база знаний.
- Риски ИБ. Качество ответов LLM можно повысить за счет добавлению в базу знаний вопросов пользователей. Однако пользователь может передать в запросе чувствительные данные, которые в итоге окажутся в распоряжении LLM. При желании эти данные сможет получить любой человек. Это значит, что в случае с LLM с данными нужно работать особенно аккуратно: обезличивать или не использовать совсем.
- Риски бесконтрольного использования. В интернете ходят анекдоты про пользователей, которые по ошибке заставляли AI-ботов генерировать гигабайты текста через API, а потом получали счета на тысячи долларов. Общий риск бесконтрольного использования оценить трудно, но все же он есть.
В целом LLM — хорошая технология, которая уже сейчас позволяет быстро и с небольшими затратами создавать функциональные, востребованные решения. Но все же это только технология со своими Pro et Contra.
В качестве заключения
Timetta продолжает использовать современные подходы к разработке и сопровождению ПО. Мы одна из первых компаний, которые начали использовать ИИ для управления проектами.
На первом этапе мы решили реализовать AI-помощника для технической поддержки пользователей на основе материалов справки. Опыт работы с данной технологией поможет в дальнейшем создавать более совершенные решения, использовать не только генеративные модели, но и прогностические для анализа рисков проектов и определения оптимальных сроков. Главное, что первый шаг в правильном направлении уже сделан.



